Results · grounded in the experiment harness
What is settled, and where the frontier is.
Four pieces of the program are done: the framing, a reproducible definition, a metric ablation, and a calibrated negative result. The in-generation controller is the open frontier, where the first coherence-preserving rhythm dial just cleared the noise floor.
Every number on this page comes from the experiment harness. Effect sizes from tiny base models (distilgpt2, gpt2-medium) are directional, not population claims, and we say so where it matters. The transferable results are the ranking of statistics, the noise calibration, and the existence of a monotone dial, not the absolute magnitudes.
A reproducible definition
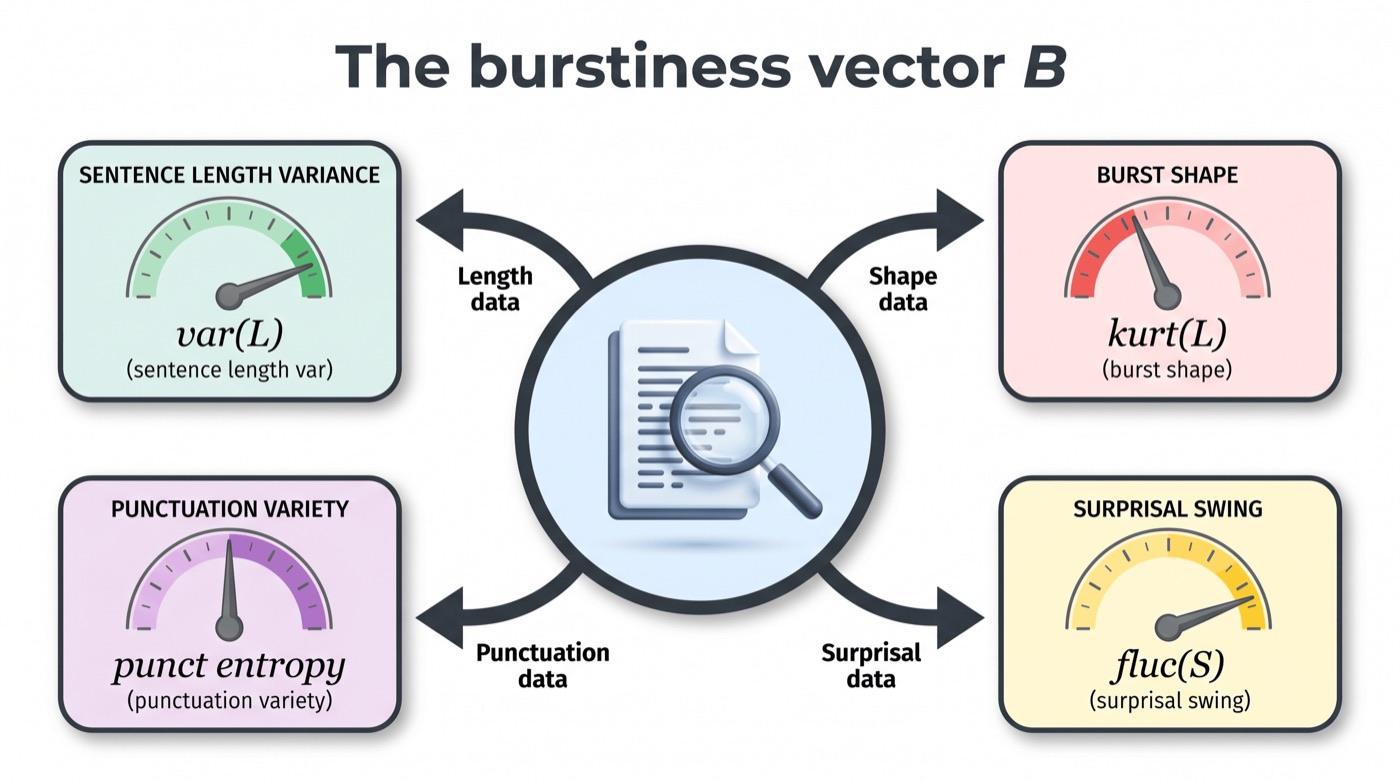
The burstiness vector.
The field's operational definition of burstiness is a detector blog post: a single scalar contrasting perplexity variation. We replace it with a decomposable, reproducible target that a controller can steer one dimension at a time.
Variance and kurtosis of sentence length, mean surprisal and local surprisal jumpiness under a fixed reference model, and the Shannon entropy of the punctuation pattern. Each component degenerates toward a small value for rhythmically flat text. On the reference demo, a human-like sample scores var(L) about 260 against about 0.49 for a flat sample, and punctuation entropy 2.00 against 0.0.
Metric ablation
The field's implicit metric is the weakest one.
Detection practice operationalizes burstiness as the standard deviation of surprisal. We ablated five surprisal statistics on two sets: a hard 4-versus-4 hand-written dev set, and a 12-versus-12 corpus of public-domain literary prose against distilgpt2 output. The ranking is the result, and it is stable across both sets.
| Statistic | Cohen's d (dev) | Cohen's d (corpus) | Verdict |
|---|---|---|---|
| mean_surprisal | +1.43 | +2.84 | Strongest separator |
| fluc_abs_diff (local jumpiness) | +1.25 | +3.15 | Best fluctuation variant |
| fluc_raw (stdev of surprisal) | +0.59 | +2.19 | Weak on the hard set |
| fluc_windowed | -0.84 | +1.16 | Reverses on dev |
| fluc_cv | -0.52 | -0.90 | Reverses on both, drop it |
Standard deviation of surprisal, the metric the field runs on, is the weakest discriminator on the hard dev set (d = 0.59, medium). Local jumpiness (mean absolute consecutive surprisal difference) and mean surprisal separate human from machine far better. The coefficient of variation reverses sign on both sets, so flat text scores higher: we drop it. The corpus effect sizes are inflated by the easy human-versus-distilgpt2 contrast; the transferable finding is the ordering, not the magnitudes. This is what fixes the vector to B = [var(L), kurt(L), mean_surprisal, fluc_abs_diff, punct_entropy].
A calibrated negative result
var(L) is noise-dominated on short generations.
The first steering arm appeared to work: a single content-matched activation vector seemed to raise var(L) from 84.7 to 137.8, a 63 percent gain at constant coherence. It did not replicate. Across five sampling seeds at the same configuration, var(L) ranged from 4.5 to 61.7, all at or below baseline. The apparent win was a sampling artifact.
The sampling variance of an estimated variance falls only as one over the sentence count. On 4 prompts times 50 tokens you have a handful of sentences, so the standard deviation of var(L) equals or exceeds its mean at every steering scale. Scaling the base model 4x to gpt2-medium did not fix it: var(L) stayed non-monotone with its std at or above its mean. The bottleneck is the estimator, not model capacity.
Single-run steering claims for var(L) are false positives. Any burstiness controller result must be reported with multi-seed averaging and a reported var(L) standard deviation, and evaluation length must clear a minimum sentence count so the estimator settles. Surfacing this before investing in training is exactly what the design gate exists to do. It also rescues every later arm, because the paired long-form protocol it forces is what finally made a real effect visible.
The in-generation controller
A boundary-steered sentence-length dial.
Token-level arms (a single activation vector, a best-of-N LoRA, GRPO) all hit the same wall: they bought variance by pushing the model off-distribution, degrading coherence, and never moved var(L) above its own noise. The fix was altitude. Steer only the sentence-ending punctuation logits toward a synthesized length plan, training-free, with the computable metric as a running discriminator. This controls var(L) at its native altitude, the boundary decision, instead of the token.
Under the paired long-form protocol the negative result forced, the dial moves. The first run, at lambda 8 over 300-token generations across 12 common-random-number pairs, gives a paired difference of +56.4 plus or minus 26.9 in realized var(L) between the low and high plans, clearing twice its standard error, while coherence is unchanged (mean surprisal 2.761 versus 2.770). Every prior arm had raised mean surprisal to buy variance; this one does not.
| Criterion | Result | Status |
|---|---|---|
| C1 monotonicity (Spearman rho over 4 dial levels) | rho = 1.00 | Pass |
| C2 effect size (Cohen's d) | d = 0.928 | Pass |
| C3 coherence drift (mean surprisal) | 0.171 | Pass |
| C4 content preservation (cosine) | 0.34 (floor 0.60) | Fail |
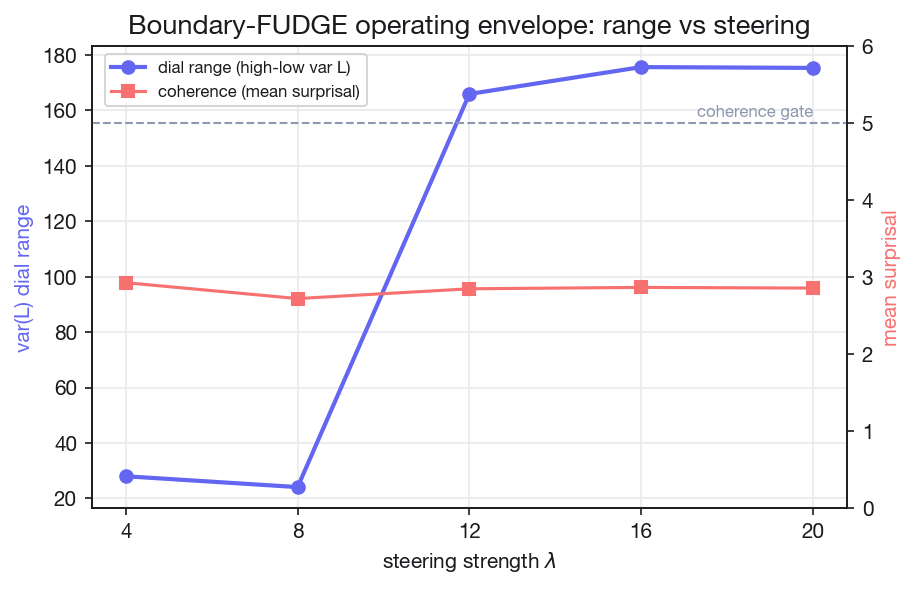
At the clean operating point (lambda 8, 300-token generations, 30 sentences, seed-averaged), expected var(L) rises monotonically across the dial: 24.59 -> 35.64 -> 39.06 -> 51.93. Three of four criteria pass. The dial is monotone, above-noise, and coherence-preserving, the first arm to be all three at once. It fails C4: at this scale it co-varies content with rhythm, so it is rhythm-plus-content control rather than rhythm-only. The fix is a content-preservation term penalizing embedding drift, or a larger base. Both paths are publishable.
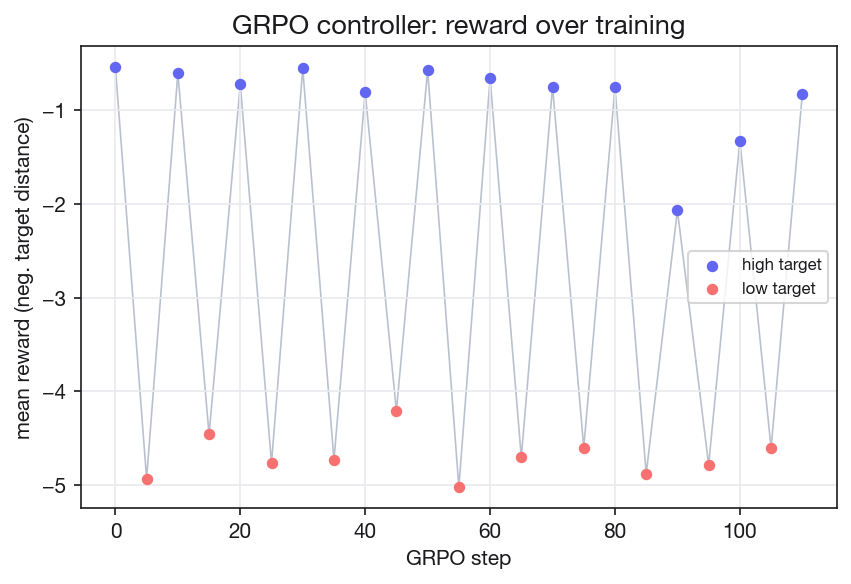
The GRPO arm
Before the boundary method broke through, GRPO trained a LoRA directly on the computable reward (no labels). The reward curve separates cleanly by target level: high-burstiness prompts hold near -0.57 to -1.08 across 110 steps while low-burstiness prompts sit around -4.7, so the reward distinguishes the two regimes. It did not, on its own, yield a reliable var(L) knob at distilgpt2 scale, the same noise wall the negative result documents. The boundary-steered dial is what finally moved the metric above noise while holding coherence.
Reproducibility
Every figure regenerates from one source of truth.
The numbers and figures on this page are not hand-entered. They regenerate from experiments/results/figures_data.json, the single source of truth for the results, via make figures. The metric itself is pure standard library with unit tests, and only the true surprisal and the generation loop need the heavier dependencies.
Explore the live corpus dashboard or read the full pipeline and harness in the repository. The controllability verdict, the lambda sweep, the GRPO curve, and the ablation each have their own JSON record under experiments/results/, so any number above is traceable to a file.